Información que quiero de mi servidor
Quiero verificar fácilmente el puerto de escucha de un proceso y mostrar fácilmente el puerto y los servicios utilizados
Un artículo que es una continuación de lo anterior.
Hola, soy un inútil.
Realmente quiero información sencilla del sistema.
Y como terminé con un comando con una legibilidad demasiado baja, intentaré que lo determine automáticamente más tarde a partir del valor de retorno de which...
Conectar pipes de esta manera lo hace completamente ilegible, así que los desglosaré.
Si lo hago como un solo comando en una línea, mucha gente se enfadará, así que no es bueno.
Pero, ¿será la magia de history lo que hace que la CLI se ensucie...?____
Cuando es largo,
set -o vi
puedes ser feliz realizando operaciones en modo vi. También es efectivo antes de configurar los mapas de teclas si no tienes teclas de flecha.
FreeBSD
echo -e "`sysctl -n hw.model`\n`printf \"%.2f GB\\n\" $(echo \"scale=2; $(sysctl -n hw.realmem) / 1024 / 1024 / 1024\" | bc)`\n\n`df -h`\n" && lsof -i -P -n | grep \"LISTEN\" | awk '{print $1 \",\" $3 \",\" $9 \"/\" $8}' | sort | uniq | column -t -s \",\"

sysctl -n hw.model Información de CPUprintf “%.2f GB\n” $(echo “scale=2; $(sysctl -n hw.realmem) / 1024 / 1024 / 1024” | bc) Memoriadf -h Discolsof * Puerto de escucha
GNU/Linux
echo -e "`grep \"model name\" /proc/cpuinfo | head -1`\n`awk '/MemTotal/ { printf \"%.2f GB\\n\", $2 / 1024 / 1024 }' /proc/meminfo`\n\n`df -h`\n" && lsof -i -P -n | grep \"LISTEN\" | awk '{print $1 \",\" $3 \",\" $9 \"/\" $8}' | sort | uniq | column -t -s \",\"
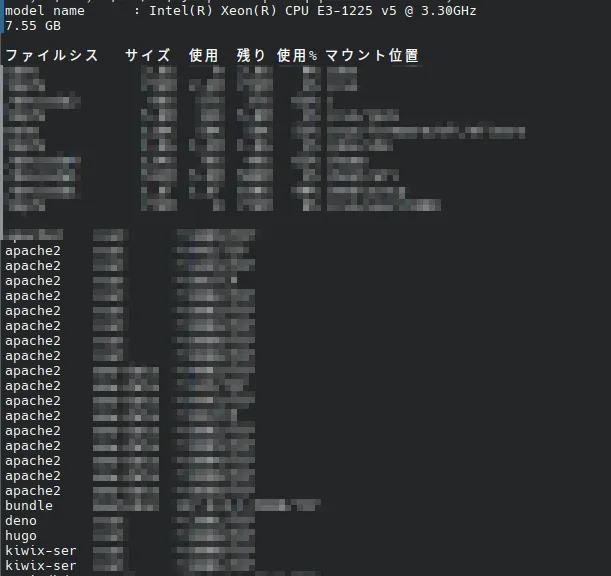
grep “model name” /proc/cpuinfo | head -1 Información de CPUawk ‘/MemTotal/ { printf “%.2f GB\n”, $2 / 1024 / 1024 }’ /proc/meminfo Memoriadf -h Discolsof * Puerto de escucha
Después de eso, estoy pasando a la siguiente ejecución con &&, pero necesito formatear todo para que sea fácilmente visible con el comando column.
En realidad, lo estoy haciendo como un solo comando para probar, pero más adelante en el código, me aseguraré de que cada parte pueda ejecutarse individualmente.
Resultado de la ejecución en ThinkPad X1 sin mosaico
$ echo -e "`grep \"model name\" /proc/cpuinfo | head -1`\n`awk '/MemTotal/ { printf \"%.2f GB\\n\", $2 / 1024 / 1024 }' /proc/meminfo`\n\n`df -h`\n" && lsof -i -P -n -l | grep \"LISTEN\" | awk '{print $1 \",\" $3 \",\" $9 \"/\" $8}' | sort | uniq | column -t -s \",\"
model name : Intel(R) Core(TM) i7-3667U CPU @ 2.00GHz
7.47 GB
Sistema de archivos Tamaño Usado Disp. Uso% Montado en
dev 10M 0 10M 0% /dev
run 3.8G 2.4M 3.8G 1% /run
/dev/sda1 234G 144G 79G 65% /
shm 3.8G 101M 3.7G 3% /dev/shm
tmpfs 3.8G 30M 3.8G 1% /tmp
tmpfs 765M 24K 765M 1% /run/user/1000
container 0 127.0.0.1:46445/TCP
cupsd 0 127.0.0.1:631/TCP
cupsd 0 [::1]:631/TCP
pulseaudi 1000 *:42787/TCP
pulseaudi 1000 *:45763/TCP
pulseaudi 1000 *:4713/TCP
sshd 0 *:22/TCP
Me preocupaba que la salida en japonés de df se detuviera en ファイルシス (Sistema de archivos), y cuando $LANG es ja_JP.UTF-8, al mirar df.c en coreutils,
No aquí...
Parece ser po/ja.po, pero ¿dónde se gestiona ahora la versión japonesa?
https://translationproject.org/domain/coreutils.html
Parece que la traducción se hace arriba, pero df no existe.
Hmm.
Sobre los archivos PO Archivos PO (utilidades GNU gettext)
Es muy irritante.