मेरे सर्वर की आवश्यक जानकारी
मैं एक प्रक्रिया के लिसनिंग पोर्ट की आसानी से जांच करना चाहता हूं और उपयोग किए गए पोर्ट और सेवा को आसानी से आउटपुट करना चाहता हूं।
उपरोक्त लेख की निरंतरता जैसा एक लेख।
नमस्ते, मैं अक्षम हूँ।
मुझे वास्तव में सरल सिस्टम जानकारी चाहिए।
और चूंकि मैंने एक ऐसा कमांड बनाया है जिसकी पठनीयता बहुत कम है, इसलिए मैं बाद में इसे which के रिटर्न मान से स्वचालित रूप से निर्धारित करने का प्रयास करूँगा...
पाइपों को इस तरह जोड़ने से यह पूरी तरह से अपठनीय हो जाता है, इसलिए मैं उन्हें अलग-अलग करूँगा।
अगर मैं इसे इस तरह एक-लाइनर के रूप में करता हूँ, तो बहुत से लोग गुस्सा हो जाएंगे, इसलिए यह ठीक नहीं है।
लेकिन क्या यह history का जादू है जो CLI को गंदा कर देता है?
जब यह लंबा हो,
set -o vi
आप vi मोड में काम करके खुश रह सकते हैं। यदि कोई तीर कुंजियाँ नहीं हैं, तो यह कीमैप सेटिंग्स से पहले भी प्रभावी है।
फ्रीबीएसडी
echo -e "`sysctl -n hw.model`\n`printf \"%.2f GB\\n\" $(echo \"scale=2; $(sysctl -n hw.realmem) / 1024 / 1024 / 1024\" | bc)`\n\n`df -h`\n" && lsof -i -P -n | grep "LISTEN" | awk '{print $1 "," $3 "," $9 "/" $8}' | sort | uniq | column -t -s ","

sysctl -n hw.model सीपीयू जानकारी
printf “%.2f GB\n” $(echo “scale=2; $(sysctl -n hw.realmem) / 1024 / 1024 / 1024” | bc) मेमोरी
df -h डिस्क
lsof * लिसनिंग पोर्ट
जीएनयू/लिनक्स
echo -e "`grep \"model name\" /proc/cpuinfo | head -1`\n`awk '/MemTotal/ { printf \"%.2f GB\\n\", $2 / 1024 / 1024 }' /proc/meminfo`\n\n`df -h`\n" && lsof -i -P -n | grep "LISTEN" | awk '{print $1 "," $3 "," $9 "/" $8}' | sort | uniq | column -t -s ","
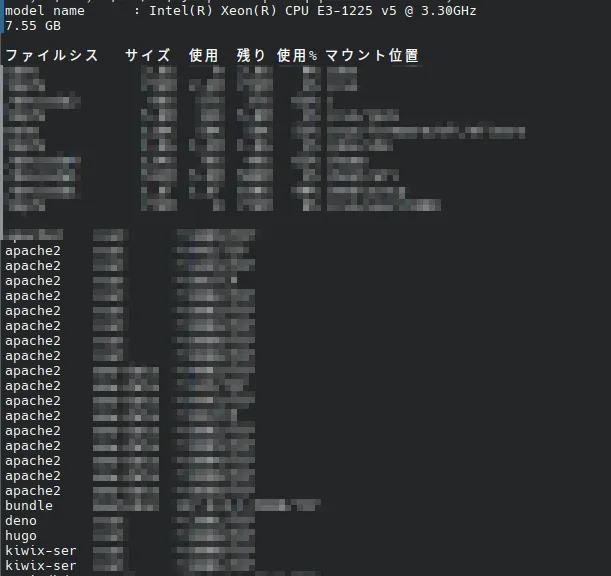
grep “model name” /proc/cpuinfo | head -1 सीपीयू जानकारी
awk ‘/MemTotal/ { printf “%.2f GB\n”, $2 / 1024 / 1024 }’ /proc/meminfo मेमोरी
df -h डिस्क
lsof * लिसनिंग पोर्ट
उसके बाद, इसे && के साथ अगले निष्पादन में पास किया जाता है, लेकिन column कमांड के साथ आसानी से देखने योग्य बनाने के लिए सब कुछ स्वरूपित किया जाना चाहिए।
वास्तव में, इसे परीक्षण के लिए एक-लाइनर के रूप में किया जाता है, लेकिन बाद में कोड में, मैं यह सुनिश्चित करूँगा कि प्रत्येक भाग को व्यक्तिगत रूप से निष्पादित किया जा सके।
थिंकपैड एक्स1 पर बिना मोज़ेक के निष्पादन परिणाम
$ echo -e "`grep \"model name\" /proc/cpuinfo | head -1`\n`awk '/MemTotal/ { printf \"%.2f GB\\n\", $2 / 1024 / 1024 }' /proc/meminfo`\n\n`df -h`\n" && lsof -i -P -n -l | grep "LISTEN" | awk '{print $1 "," $3 "," $9 "/" $8}' | sort | uniq | column -t -s ","
model name : Intel(R) Core(TM) i7-3667U CPU @ 2.00GHz
7.47 GB
फाइलसिस्टम आकार उपयोग शेष उपयोग% माउंट स्थान
dev 10M 0 10M 0% /dev
run 3.8G 2.4M 3.8G 1% /run
/dev/sda1 234G 144G 79G 65% /
shm 3.8G 101M 3.7G 3% /dev/shm
tmpfs 3.8G 30M 3.8G 1% /tmp
tmpfs 765M 24K 765M 1% /run/user/1000
container 0 127.0.0.1:46445/TCP
cupsd 0 127.0.0.1:631/TCP
cupsd 0 [::1]:631/TCP
pulseaudi 1000 *:42787/TCP
pulseaudi 1000 *:45763/TCP
pulseaudi 1000 *:4713/TCP
sshd 0 *:22/TCP
मुझे चिंता है कि df का जापानी आउटपुट फाइलसिस्टम पर रुक जाता है जब $LANG ja_JP.UTF-8 है, coreutils के df.c को देखने पर
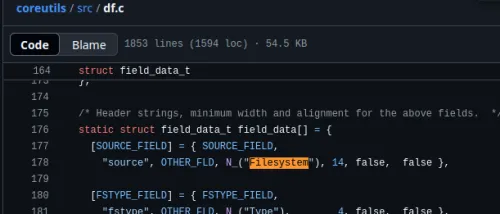
यह यहाँ नहीं है...
यह po/ja.po लगता है, लेकिन जापानी संस्करण अब कहाँ प्रबंधित किया जा रहा है?
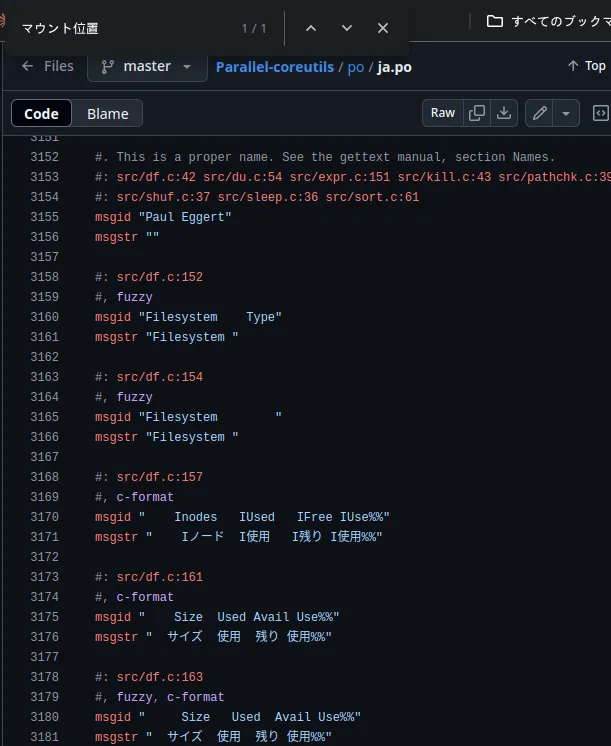
https://translationproject.org/domain/coreutils.html
ऐसा लगता है कि ऊपर अनुवाद किया गया है, लेकिन df मौजूद नहीं है।
हम्म।
पीओ फाइलों के बारे में पीओ फाइलें (जीएनयू गेटटेक्स्ट यूटिलिटीज)
यह बहुत परेशान करने वाला है।