Informações Desejadas do Meu Servidor Pessoal
Quero verificar convenientemente as portas de escuta de um processo e exibir facilmente as portas e serviços em uso
Um artigo que parece uma continuação.
Olá, sou um inútil.
Eu realmente quero informações simples do sistema.
E como um comando com legibilidade muito baixa foi criado, vou fazer com que ele determine automaticamente a partir do valor de retorno de which mais tarde...
Conectando pipes desta forma, não há legibilidade alguma, então vou separá-los.
Normalmente, se você fizer isso com um one-liner, muitas pessoas ficarão irritadas, então não é bom.
Mas eu me pergunto se a bagunça na CLI é a magia do history____
Quando é longo,
set -o vi
você pode ser feliz realizando operações no modo vi. É também eficaz antes das configurações de mapeamento de teclas, se você não tiver as teclas de seta.
FreeBSD
echo -e "`sysctl -n hw.model`\n`printf "%.2f GB\n" $(echo "scale=2; $(sysctl -n hw.realmem) / 1024 / 1024 / 1024" | bc)`\n\n`df -h`\n" && lsof -i -P -n | grep "LISTEN" | awk '{print $1 "," $3 "," $9 "/" $8}' | sort | uniq | column -t -s ","

sysctl -n hw.model Informações da CPUprintf “%.2f GB\n” $(echo “scale=2; $(sysctl -n hw.realmem) / 1024 / 1024 / 1024” | bc) Memóriadf -h Discolsof * Portas de escuta
GNU/Linux
echo -e "`grep "model name" /proc/cpuinfo | head -1`\n`awk '/MemTotal/ { printf "%.2f GB\n", $2 / 1024 / 1024 }' /proc/meminfo`\n\n`df -h`\n" && lsof -i -P -n | grep "LISTEN" | awk '{print $1 "," $3 "," $9 "/" $8}' | sort | uniq | column -t -s ","
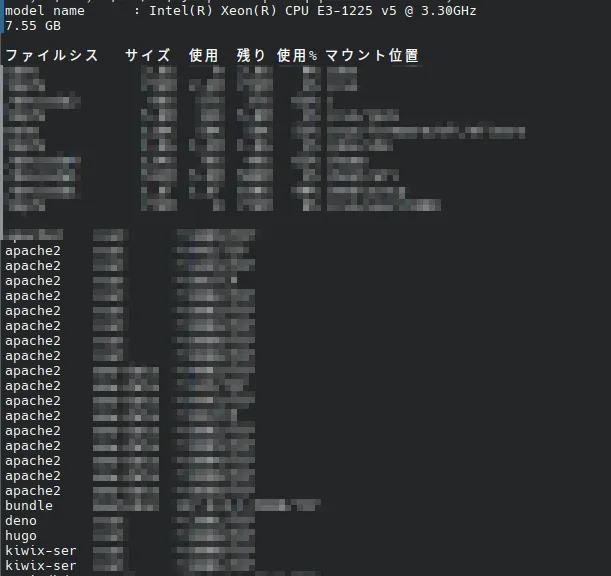
grep “model name” /proc/cpuinfo | head -1 Informações da CPUawk ‘/MemTotal/ { printf “%.2f GB\n”, $2 / 1024 / 1024 }’ /proc/meminfo Memóriadf -h Discolsof * Portas de escuta
Depois disso, é passado para a próxima execução com &&, mas tudo deve ser formatado para ser facilmente legível com o comando column.
Na verdade, estou fazendo isso como um one-liner para testes, mas mais tarde no código, farei com que cada parte possa ser executada individualmente.
Resultado da execução no ThinkPad X1 sem mosaico
$ echo -e "`grep "model name" /proc/cpuinfo | head -1`\n`awk '/MemTotal/ { printf "%.2f GB\n", $2 / 1024 / 1024 }' /proc/meminfo`\n\n`df -h`\n" && lsof -i -P -n -l | grep "LISTEN" | awk '{print $1 "," $3 "," $9 "/" $8}' | sort | uniq | column -t -s ","
model name : Intel(R) Core(TM) i7-3667U CPU @ 2.00GHz
7.47 GB
Sistema de arquivos Tamanho Usado Disponível Uso% Ponto de montagem
dev 10M 0 10M 0% /dev
run 3.8G 2.4M 3.8G 1% /run
/dev/sda1 234G 144G 79G 65% /
shm 3.8G 101M 3.7G 3% /dev/shm
tmpfs 3.8G 30M 3.8G 1% /tmp
tmpfs 765M 24K 765M 1% /run/user/1000
container 0 127.0.0.1:46445/TCP
cupsd 0 127.0.0.1:631/TCP
cupsd 0 [::1]:631/TCP
pulseaudi 1000 *:42787/TCP
pulseaudi 1000 *:45763/TCP
pulseaudi 1000 *:4713/TCP
sshd 0 *:22/TCP
Fiquei curioso por que a saída em japonês de df parava em ファイルシス (Sistema de arquivos), então, quando $LANG é ja_JP.UTF-8, ao olhar para df.c em coreutils, vejo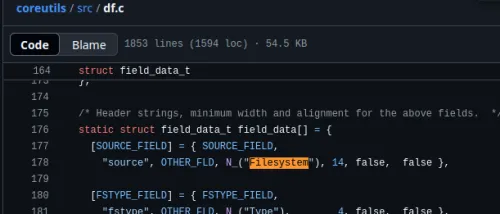
Não é aqui...
Parece ser po/ja.po, mas onde a versão japonesa é gerenciada agora?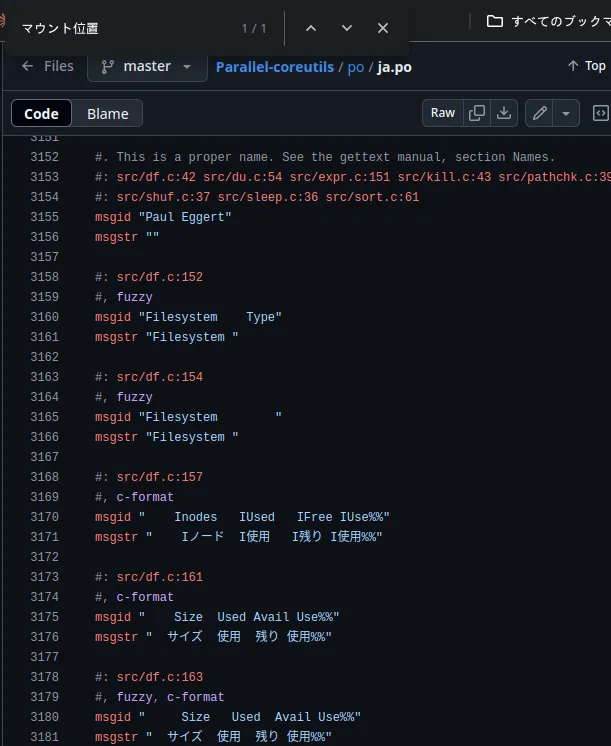
https://translationproject.org/domain/coreutils.html
Parece que a tradução é feita acima, mas df não existe.
Hmm.
Sobre arquivos PO PO Files (GNU gettext utilities)
É muito irritante.