Cómo verificar fácilmente los puertos de escucha de los procesos y generar los puertos y servicios utilizados
Hola, soy Munou (Incompetente).
Vaya, vaya, parece que se ha utilizado en el título una frase que me suena de algún sitio...
Todavía pienso de vez en cuando que es un buen nombre de sitio. Por cierto, en mi chequeo médico de hoy, mi presión arterial fue de 60-100, lo cual es perfectamente hipotenso.
La segunda vez que me la midieron, la presión arterial era muy baja, así que, como era de esperar, usaron el primer valor.
Introducción
De repente, pensé:
"Quiero generar claramente qué puertos se están utilizando y qué servicios corresponden a esos puertos".
La razón es:
- Quiero verificar y generar fácilmente la información sin necesidad de un diagrama de configuración del servidor mientras lo opero personalmente.
- Quiero generar la salida en formato Markdown o como archivo de texto.
- Verificación de puertos en uso
Para ser honesto, a medida que he ido ejecutando más cosas por mi cuenta, a menudo me pregunto: "¿Qué puerto estaba usando para esto?".
A medida que la información que necesito se acumula, quiero automatizarla hasta cierto punto y poder verificarla fácilmente como un archivo .md.
Por cierto, la razón por la que insisto en los archivos de texto es porque
facilita el manejo de los datos.
Hablaré más sobre este punto más adelante.
Simplemente, con solo escribir esto:
lsof -i -P -n | grep "LISTEN" | awk '{print $1 "," $3 "," $9}' | sort | uniq
obtendrás esto:
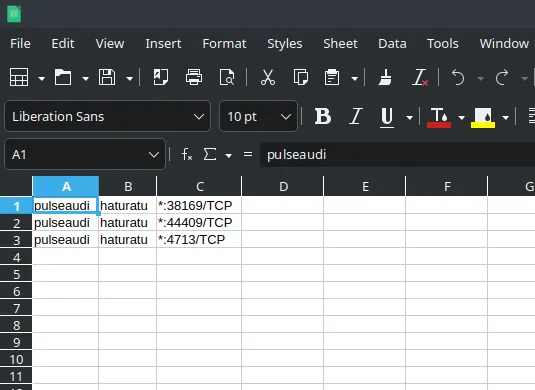
$ lsof -i -P -n | grep "LISTEN" | awk '{print $1 "," $3 "," $9}' | sort | uniq
pulseaudi,haturatu,*:38169
pulseaudi,haturatu,*:44409
pulseaudi,haturatu,*:4713
Genera la salida de esta manera.
Por cierto, el resultado es el mismo sin las opciones de lsof, pero parece que es diferente en la versión BSD, así que he incluido todas las opciones.
Convertir a CSV
Aunque a menudo se discuten varios formatos de archivo, a mí me gusta el formato CSV.
Para ser honesto, creo que CSV no es una mala opción cuando se trabaja con archivos CSV. La única cosa obvia es que si reemplazas comas con sed, también podrías reemplazar comas que se usen dentro de una cadena de texto.
TSV aún no me resulta familiar en general, así que prefiero CSV. (Para ser honesto, si voy a reemplazar con sed, ¿qué es menos propenso a errores, una coma o un tabulador...?)
Me he desviado un poco del tema, pero si lo conviertes fácilmente a CSV, puedes copiarlo y pegarlo directamente en Excel, y la legibilidad es alta incluso si solo lo abres.
Simplemente, puedes abrirlo fácilmente con LibreOffice o similar redirigiendo la salida estándar a un archivo .csv. A continuación, añadiré información de TCP y UDP.
$ lsof -i -P -n | grep "LISTEN" | awk '{print $1 "," $3 "," $9 "/" $8}' | sort | uniq > test.csv
Se verá así:
De esta manera,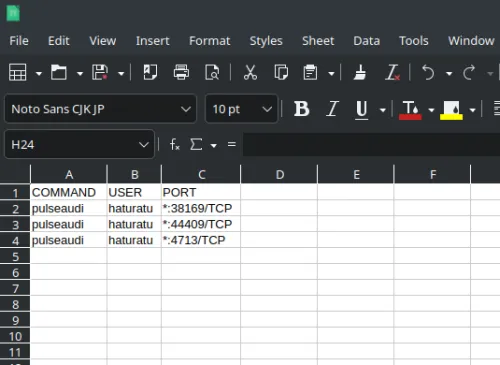
podría ser bastante fácil de visualizar.
Para ser honesto, al principio estaba imprimiendo de forma un poco tosca con print " " sin usar espacios como printf %10s, pero como comando para convertir a formato CSV, creo que es más claro y fácil de leer pasar la salida al comando column mediante una tubería...
Si lo conviertes a formato Markdown
Al principio pensé en seguir el formato Markdown y usar tablas, pero no me gustan mucho las tablas en formato Markdown, así que creo que es mejor usar "```" para facilitar el copiar y pegar.
Si es necesario, lo imprimiré con awk.
La razón por la que quiero generar la salida en formato Markdown es porque si lo ejecuto como un cron que hace push regularmente a un repositorio privado en Github o similar, puedo verificarlo fácilmente en cualquier momento.
Considerando otras cosas necesarias
Luego, para verificar la capacidad del disco, usaría df -h, vmstat, free, etc., pero eso ya sería más bien una monitorización de recursos de todo el sistema, así que quizás sería mejor extraer información de /proc/cpuinfo, /proc/meminfo, etc.
Sería aún mejor si la información de las tablas de la base de datos fuera fácil de visualizar. Si lo hiciera, ejecutaría comandos relacionados con la base de datos con which * y solo mostraría la información específica de la base de datos para aquellos que devuelvan un código de estado 0, lo cual sería más pulcro. Pero me da un poco de pereza.
Los diagramas de configuración varían bastante de una persona a otra, y entiendo que los documentos de diseño detallados para productos de middleware son, por supuesto, necesarios, pero si la visión general del sistema no está consolidada en un solo lugar, es difícil de verificar. Así que me pregunto si hay alguna forma de gestionarlo más fácilmente a nivel personal.
Es fácil crear diagramas con herramientas como draw.io, pero también quiero reducir el costo de verificación hasta la creación de esos diagramas.
Extra: El silencio de Wireguard
Por cierto, mientras lo hacía, me pregunté: "Wireguard está funcionando como UDP51820 con lsof, ¿por qué no se muestra?". Y encontré la respuesta.
the wireguard not listening on port after started
WireGuard + VPS en Raspberry Pi
Parece que es porque funciona como un módulo del kernel. Según mi propia interpretación, Wireguard opera en la capa 3, y lsof solo muestra "archivos abiertos por procesos", así que pensé que por eso no se mostraba. ¿Estoy equivocado?
Por cierto, la documentación en japonés de Red Hat es bastante fácil de entender.
Capítulo 8. Configuración de una VPN WireGuard
Y eso es todo por hoy. Si se me ocurre algo más, puede que escriba una continuación, o puede que no.
Gracias de nuevo.